
📖 About Me
Hello, I am a Senior Algorithm Expert in the Multimodal Group at 01.AI. My research interests cover computer vision, vision and language, and multimodal generation. Specifically, I focus on image generation, video generation, and speech generation, with precise control over these processes through text, images, and speech. Before joining 01.AI, I was the head of the AI department at Xinhua Zhiyun, an Alibaba-affiliated company. Prior to that, I was the co-founder and CTO of UniUbi. I received my master’s degree in 2015 from the Institute of Automation, Chinese Academy of Sciences, under the supervision of Professor Stan Z. Li. During my career, I have been dedicated to advancing AI research and have successfully implemented several AI applications, particularly in the areas of content creation and enhancement. If you are interested in collaborating with me to explore the development of next-generation multimodal models, please feel free to contact me via email at (wangtaomarvel at gmail dot com).
💻 Projects
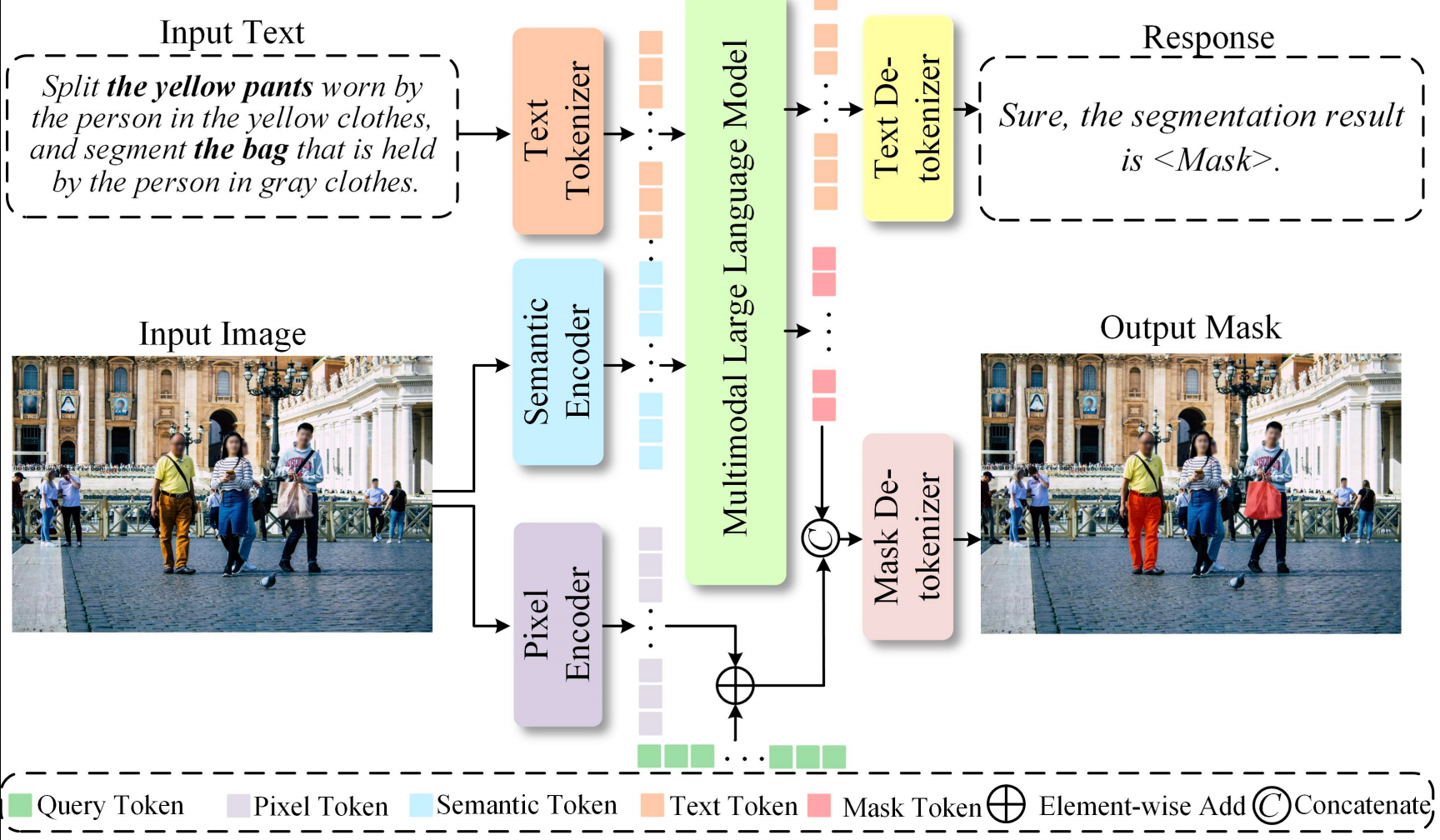
Adaptive-Length Tokenizer for Autoregressive Mask Generation
- Project Duration: 2025
- Propose ALTo, an adaptive-length mask tokenizer that, for the first time, enables the model to autonomously determine the number of mask tokens based on the complexity of the input mask.
- Develop ALToLLM, which integrates ALTo into a multimodal large language model (MLLM), enabling adaptive mask token generation for object segmentation tasks.

Learning Hierarchical Mask Tokens for Image Segmentation with Large Multimodal Model
- Project Duration: 2025
- Compresses a full mask into ≤32 discrete tokens, so inference reduces to the LLM’s native next-token prediction paradigm.
- Recovers masks without the original image, removing the extra segmentation decoder and simplifying the pipeline.
- Hierarchical Mask Tokens support progressive detail refinement for high-quality masks.
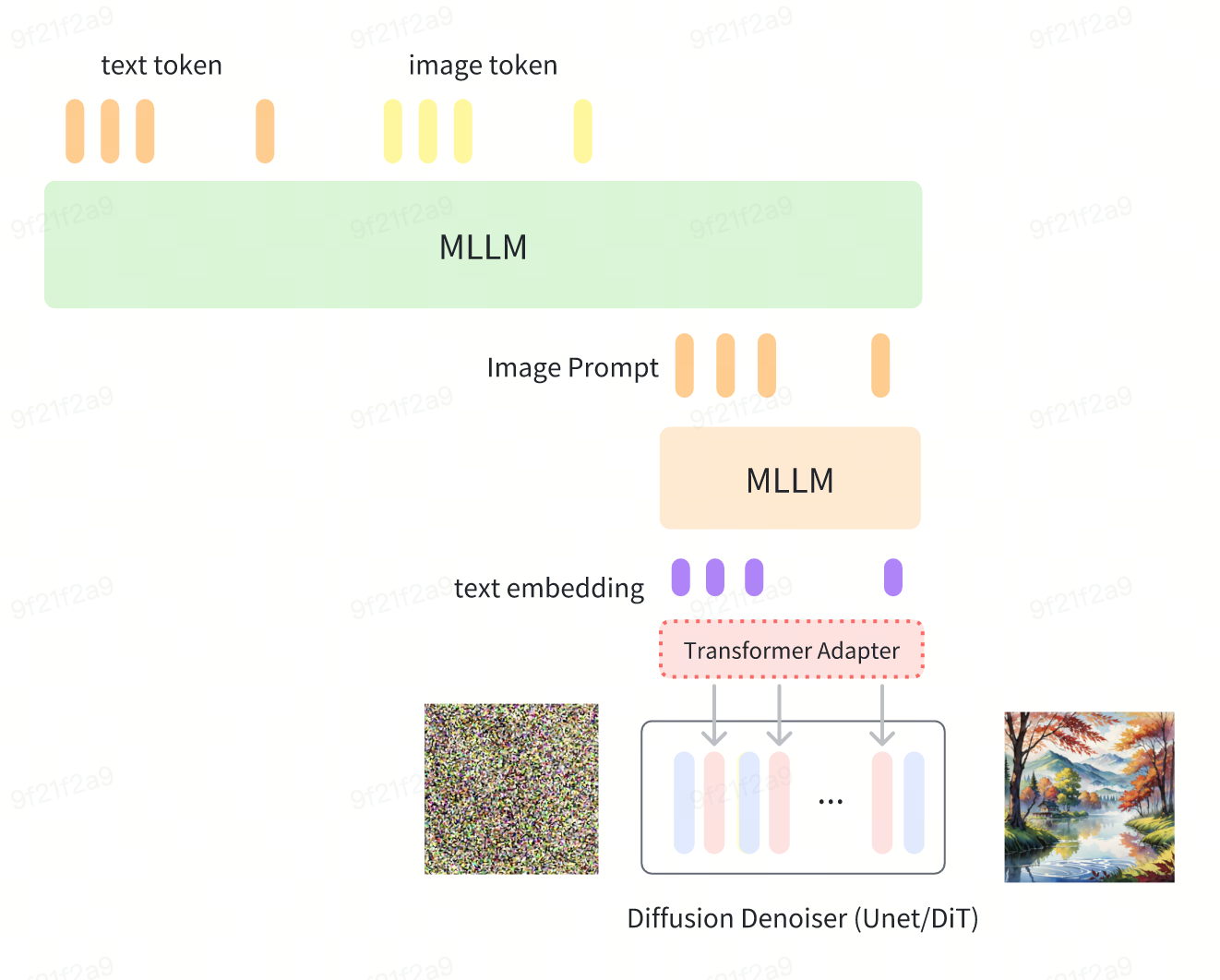
Text-to-Image Generation Based on Multimodal Large Models
- Project Duration: 2024
- This is an Any-to-Any Multimodal LLM project that supports using both images and text as conditions simultaneously.
- By leveraging the powerful MLLM, it achieves superior text encoding and offers better prompt following compared to open-source models.
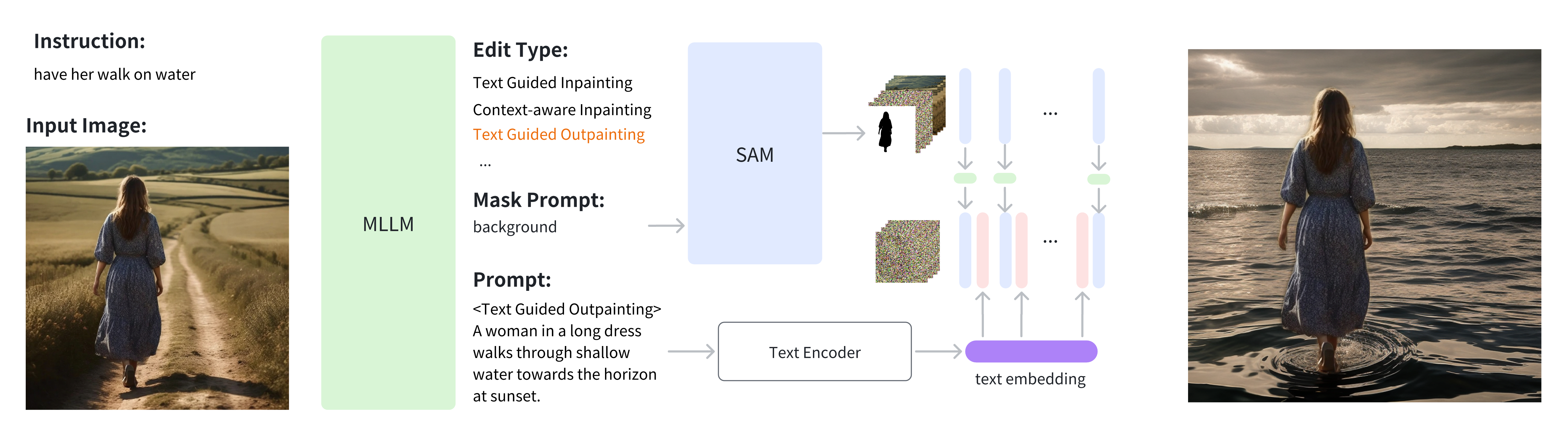
Intelligent Image Editing Based on Multimodal Large Models
- Project Duration: 2024
- Enables various intelligent image editing tasks.
- Automatically generates Edit Type, Mask Prompt, and Output Image Prompt based on MLLM.
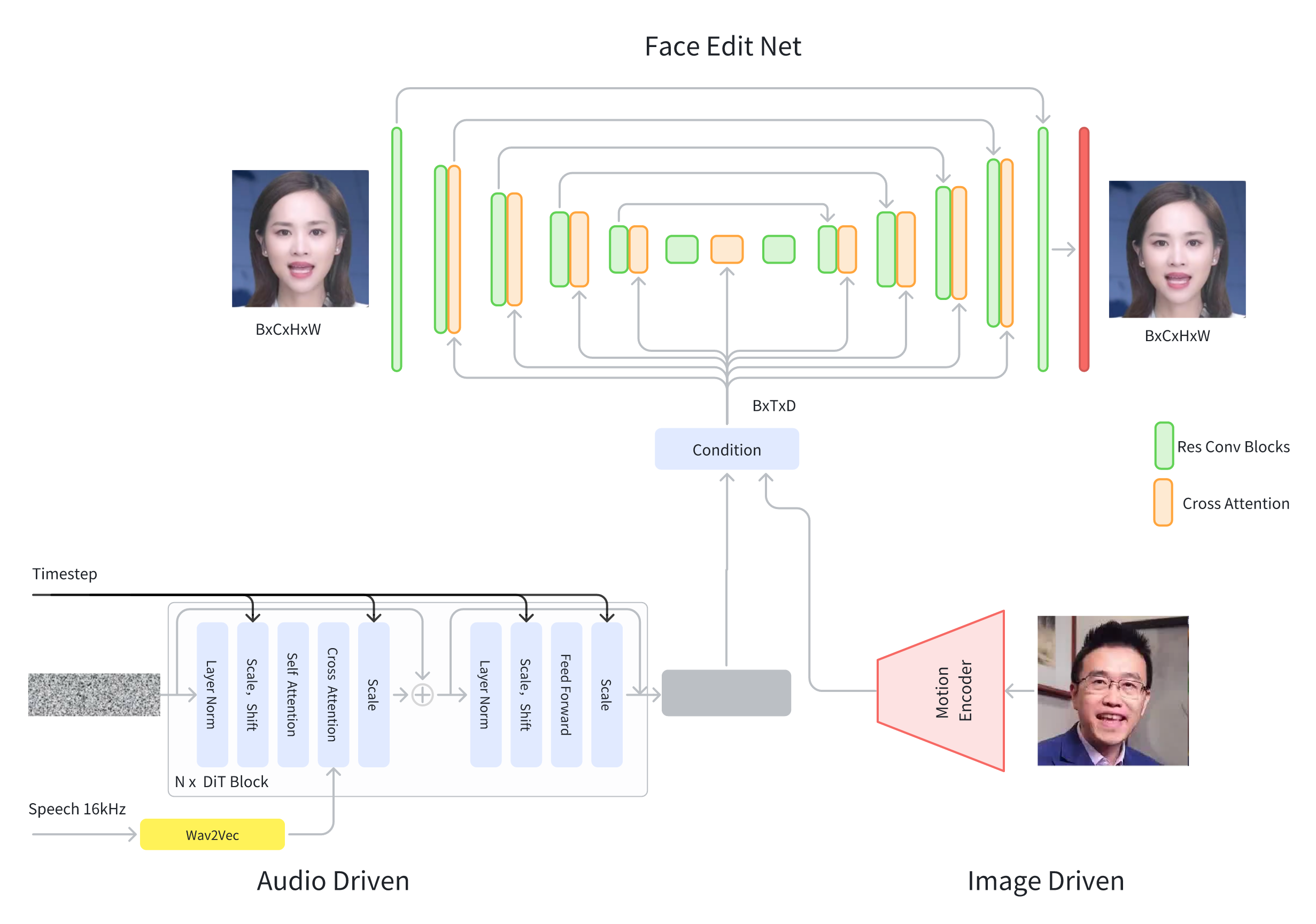
Multimodal-Driven Digital Human Model for Thousands of Users
- Project Duration: 2021-2023
- Supports customization of digital humans for multiple users (>1000) within a single model.
- Supports multiple input types, including voice, singing, and images.
- Extremely fast inference speed, utilizing RTX 4090 for 10x video synthesis speed.
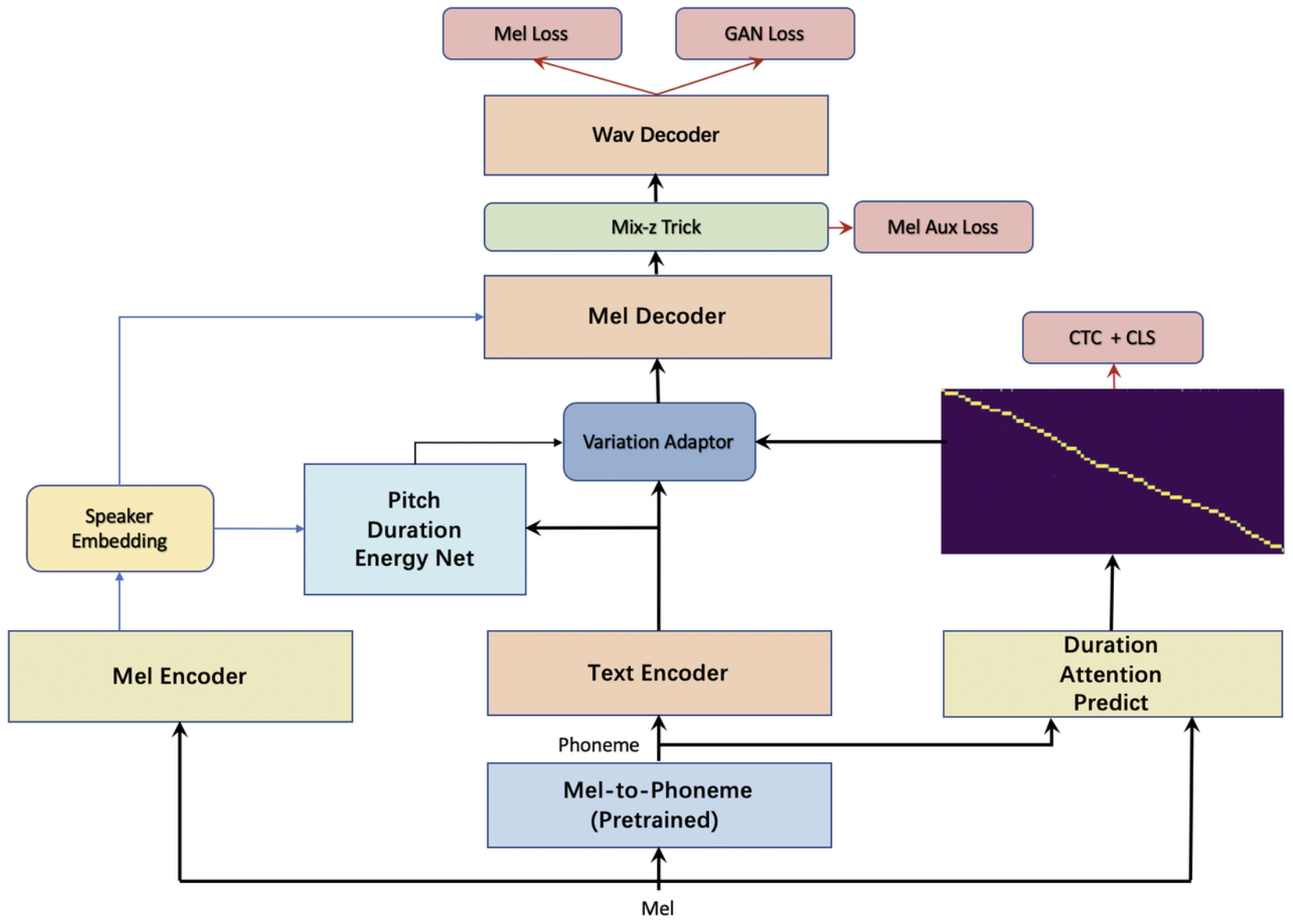
Self-Supervised Multi-Speaker TTS Model
- Project Duration: 2022-2023
- Seamlessly integrates phoneme prediction, phoneme alignment, and vocoder to achieve true self-supervised training, leveraging the value of big data.
- Supports multi-speaker training and zero-shot voice cloning.
- Non-autoregressive design, enabling fast inference speeds.
All Speakers in One Model
Zero Shot Original Voice
Zero Shot Synthesized
📝 Publications
- Tao Wang, Jianwei Yang, Zhen Lei, Shengcai Liao, Stan Z. Li. “Face Liveness Detection Using 3D Structure Recovered from a Single Camera”. ICB2013. Madrid, Spain, June 4-7, 2013. Citations:162
- Tao Wang, Changxu Cheng, Lingfeng Wang, Senda Chen, Wuyue Zhao. “HiMTok: Learning Hierarchical Mask Tokens for Image Segmentation with Large Multimodal Model”. arXiv:2503.13026. Accepted by ICCV 2025. the code is at GitHub
- Lingfeng Wang*, Hualing Lin*, Senda Chen*, Tao Wang*, Changxu Cheng, Yangyang Zhong, Dong Zheng, Wuyue Zhao. “ALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation”. arXiv:2505.16495. Accepted by NeurIPS 2025. the code is at GitHub
🎖 Honors and Awards
- National Scholarship three times
- Champion of the first Alibaba Tianchi Big Data Competition, with a prize of 200,000 RMB
- Champion of the 2014 Double 11 Tmall Recommendation Algorithm Challenge, with a prize of 1,000,000 RMB